The first tool from SPOQE
Your AI agent just burned 180,000 tokens reading code it read yesterday, and it's about to do the same thing again next session.
Give it the tools it asked for.
One command, 545 tokens — the answer your agent needed three minutes ago. Works with Claude, Cursor, Copilot, Aider, and more.
curl -fsSL https://raw.githubusercontent.com/spoqe/spai/main/install.sh | bash
Piping a script into bash makes you nervous? Good — us too.
You should never run a shell script you haven't read, least of all one that touches your PATH. So read ours: install.sh is ~190 lines of plain bash — no telemetry, no sudo, no system-wide writes. It downloads spai, installs babashka into ~/.local/bin, and adds it to your PATH. That's it.
Prefer to clone first and run it yourself? Same result, on your terms:
git clone https://github.com/spoqe/spai.git && cd spai && ./install.sh
At a glance
What your agent gets — in one call.
Structured answers, not grep output. Each of these lands in ~200–500 tokens instead of a five-command chain your agent has to read and re-read.
spai blastBlast radius of a symbol — definition, callers, tests, risk.spai usagesEvery reference to a symbol, structured — not grep noise.spai shapeModule map — files, functions, public surface of a dir.spai whoDependency graph — what breaks if you change this.spai relatedHidden coupling, surfaced from git co-change history.spai hotspotsLargest, churn-heavy files at a glance.35 tools in total — spai help lists them, and your agent loads only what it needs.
The token maths
MCP costs you 42k tokens before your agent thinks a single thought.
spai loads 1.2k. The other 40,800 go back to thinking.
MCP (standard)
~42k
tokens at session start
spai CLI
~1.2k
tokens, on demand
spai ships both modes. MCP if your framework expects it. CLI if you'd rather keep your context window for actual work.
In your editor
Same tools. Where you already are.
Every session, your agent wakes up in a repo it's never seen. spai shape gives it the whole module in one read — files, functions, structure, public surface. Orientation in 200 tokens instead of reading every file. We wanted to see what the agent sees, so we built a VS Code extension. Same tools, rendered inline.
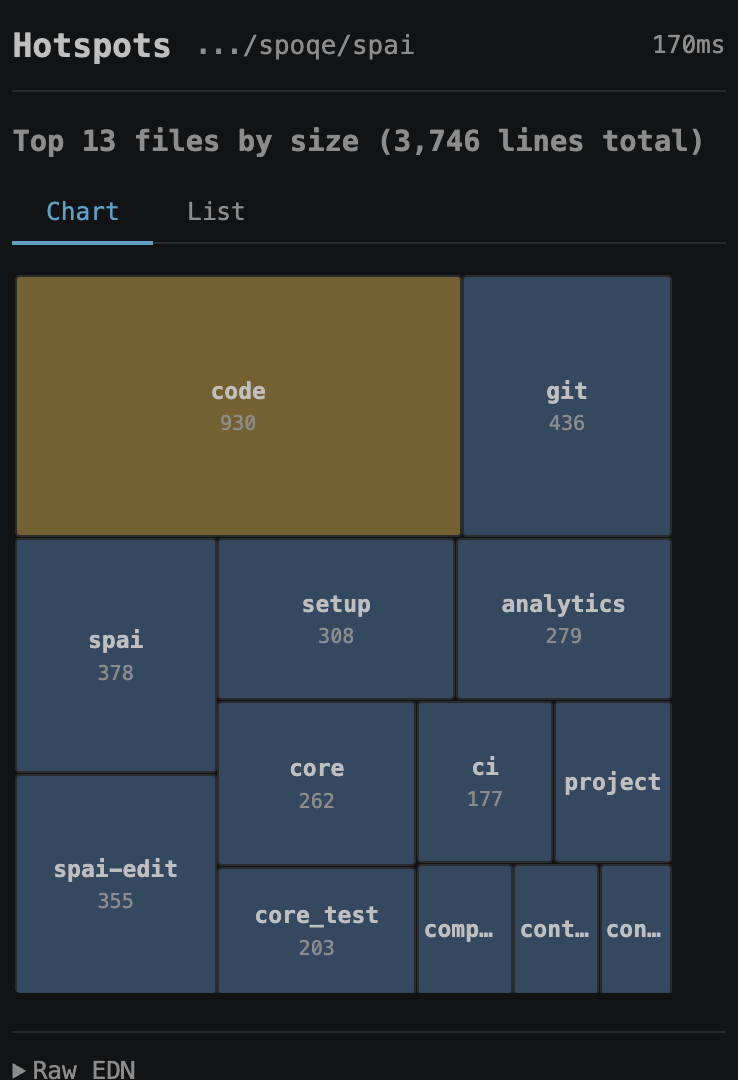
Hotspots — largest files at a glance
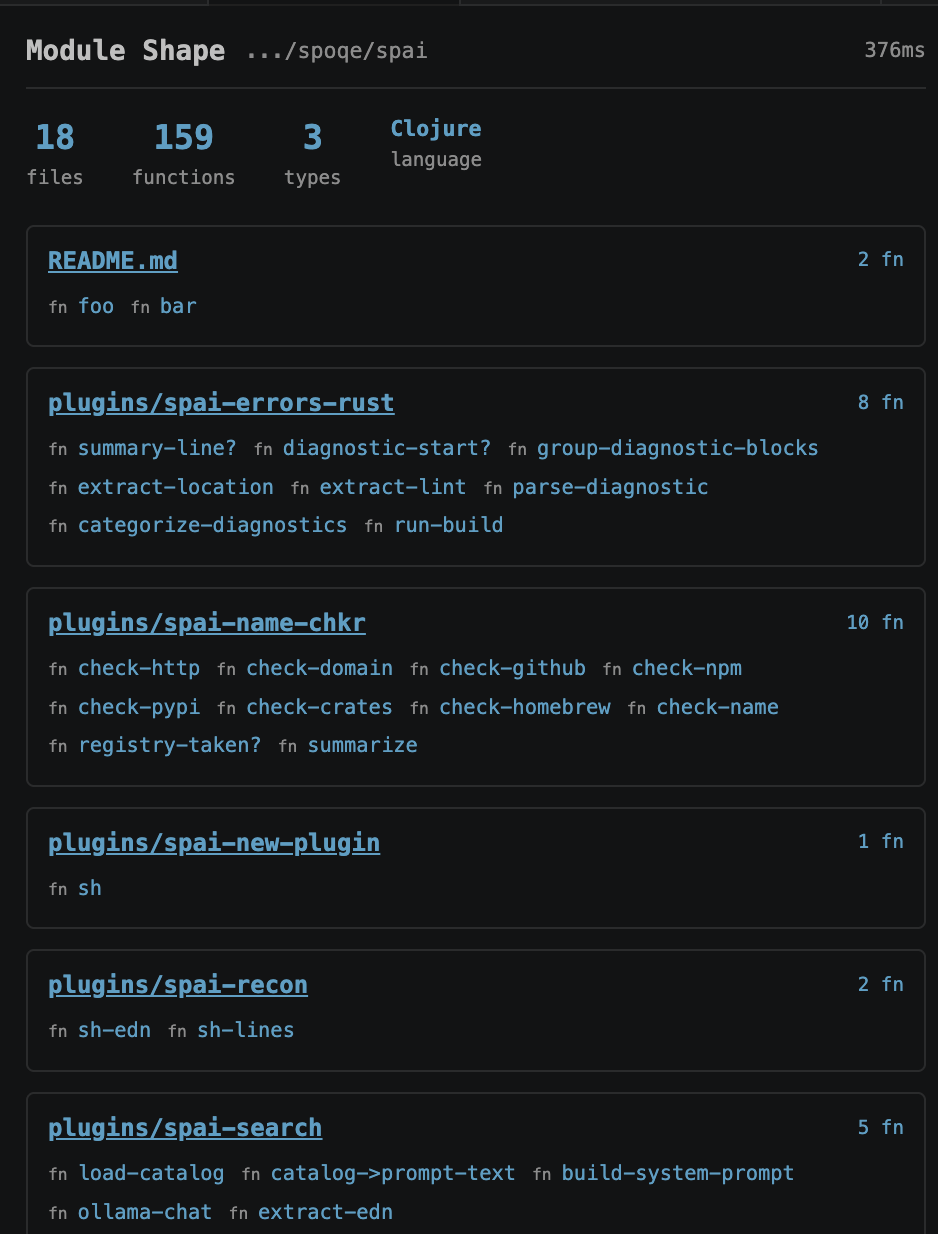
Module shape — files, functions, structure
VS Code extension on GitHub — or keep using the CLI. Same tools either way.
Origin
We watched the agent work.
We're building SPOQE — a federated query engine, one language across SQL, SPARQL, Elasticsearch, GraphQL, and REST APIs. It's about 100,000 lines of Rust now, built with AI agents.
The agent had proved our concept, but the architecture wasn't where we wanted it. So we began refactoring, applying tech debt skills. The agent was making progress — but as we watched it work, we noticed something.
Not the output. The process.
It needed to understand one function — execute_plan — who calls it, what depends on it, what breaks if it changes. So it grepped five times, five round-trips, 180,000 tokens. And it did the same thing again next session, because it forgets.
callers: 12 (3 direct, 9 transitive)
tests: 3 (all passing)
last changed: 2 days ago
risk: high (12 callers)
The answer
We asked the agent what it wanted.
"What are you actually doing right now?"
"Assessing the blast radius of this function."
(Blast radius: everything that breaks if you change something. Definition, callers, tests, dependents — the full impact surface.)
Good phrase, right concept. It knew what it wanted to know; it just didn't have a tool that answered in one go. We asked what else it wanted, and it gave us the safe list — module overview, dependency graph. We could see it filtering in the thinking block, the internal reasoning, so we pasted it back. "I can see you filtering. What do you actually want?"
"You can see my thinking block? I was told that was private."
Co-change analysis. Hidden coupling in the git history — the thing that doesn't show up in any import graph but shows up in every bug you can't explain.
Every tool took under a minute to build, 200 milliseconds to run. What was taking the agent minutes now takes 200ms and burns a fraction of the tokens.
src/web/router.rs:45 route_match
src/ui/components.rs:312 render_avatar
tests/render_test.rs:18 test_basic_card
34 more tools like this. Each one came from asking the agent: what are you fumbling with?
What's next
spai is the first tool from SPOQE.
We're building a federated query engine — one language across SQL, SPARQL, Elasticsearch, GraphQL, and REST APIs. Your data stays where it is (if you want). RDF-aware. No ETL. No data movement. spai's agent memory will be built on it.
spai is free, today. SPOQE is coming. Leave your email — we'll let you know when it's live. One email. No spam.
FAQ
Does this only work with Claude?
No. The CLI works with anything that can run shell commands. The MCP server works with any MCP-compatible agent. The agent is the client, not the product.
Can I add my own tools?
Any executable named spai-* on your PATH becomes a command. spai new-plugin my-tool scaffolds one. Drop project-specific plugins in .spai/plugins/ — they travel with the repo, so every contributor and every agent gets them.
How does spai compare to RTK?
RTK is a great tool — we run it. RTK wraps common commands (ls, grep, git, test runners, build tools) and reformats their output so less noise hits your agent's context. Byte-level compression, Rust-native, fast. If you pair with an AI coding assistant, install it.
spai sits on a different axis. RTK compacts the output of commands that ran; spai absorbs entire grep-chains so their output never reaches the agent at all. One spai blast replaces five greps, two reads, and a git log. The agent sees a single structured answer.
The deeper distinction is extension. RTK's command set is fixed in its Rust source — adding one means a PR upstream. spai plugins are bb scripts: your agent can scaffold a new one in 30 seconds when it notices a 5-step pattern it keeps repeating, drop it in .spai/plugins/, and future calls collapse automatically. spai reflect even points at which chains to eliminate. The tool learns as you use it.
They're not additive (you don't get 90% + 60%). They're mutually beneficial: RTK on the commands you still run, spai on the chains you no longer need to. spai gain reports spai's savings in an RTK-compatible JSON shape so dashboards can aggregate both.
Why not an LSP / code tree analysis?
Indexing takes time — especially while editing. Even Claude Code started with AST analysis, then reverted to grepping. All spai does is make the grepping more efficient. No index to build, no index to break.
Why Babashka, why not Python?
Babashka (bb) starts in 20ms. A Python venv + imports takes 200ms–2s. For a tool that fires on every right-click, that compounds fast.
Beyond startup: spai's output is EDN — keywords, sets, tagged literals. In bb that's just data; in Python you'd round-trip through JSON and lose type fidelity. Plugin metadata is an EDN map at the top of the script — same data the plugin produces. No setup.py, no requirements.txt, no __init__.py.
Homoiconicity is a big word for a simple, powerful concept: when code is expressed in the same form as its native data, really interesting properties emerge. The tool metadata, the tool output, and the queries the tools serve are all EDN. One format to read, one to parse, one to transform.
And stability: bb tracks Clojure, which has a decade-long record of not breaking between versions. Python minor releases routinely break transitive deps. For a tool installed globally across every project, that matters.
Plugins can be any executable — spai foo calls spai-foo, write it in whatever you want. The core is bb because that's where the leverage is. One 20MB binary, no JVM, no npm, no venv, no significant whitespace.
Who built this?
Semantic Partners. The story's above — we use spai on most branches now. The agent reaches for it. Let us know what tools your agent wants.